En Bosonit hemos dado comienzo a los TechXperience con una ponencia sobre ‘Arquitectura de capas’. Las TechXperience son un serial de eventos de cultura tecnológica, divididos por áreas de conocimiento destinados a la creación y enriquecimiento del conocimiento nuestra comunidad.
El objetivo de ellos es mejorar la visibilidad y las capacidades de las personas que hacemos Bosonit para compartir nuestro conocimiento y estar al día de todas la novedades y actualizaciones tecnológicas, difundir y enriquecer nuestro talento mediante la divulgación de las experiencias en proyectos que han experimentado nuestros compañeros para que nos sirve de inspiración y de ayuda en nuestro día a día. Estas sesiones estarán centralizadas en las áreas de conocimiento que hacen diferencial a Bosonit: Big Data, Machine Learning / Data Science, DevOps & Cloud, Desarrollo y Data Management / Business Intelligence.
La primera de las sesiones fue protagonizada por nuestro compañero David Ortega Cruz, consultor de BI, y trato sobre “Experiencias en el tratamiento de datos”. En ella discurrió sobre la visión del diseño arquitectura y modelizado de bases de datos para Business Intelligence y sobre arquitecturas, modelizado y Data Management en grandes empresas para la creación de bases de datos. La experiencia de David le acredita como una voz autorizada y de referencia dada su experiencia y formación.
¿Quién es David Ortega Cruz?
David Ortega Cruz forma parte de Bosonit desde hace casi cinco años. Cuenta con estudios en Ingeniería Técnica Industrial con especialidad en Electrónica, Grado en Ingeniería Informática y un Master en Análisis y Visualización de Datos Masivos. En la aplicación de sus conocimientos los roles que desempeña normalmente en los proyectos son de Data Engineer, BI Consultant o Big Data Developer. Ha trabajado en proyectos para la arquitectura, modelado y desarrollo de bases de datos, así como de procesos de carga de grandes volúmenes de datos. Creando desde cero las estructuras y procesos.
También ha trabajado dentro de un equipo de Data Governance, en donde revisaba procesos, documentación, diccionarios, tablas, etc. Además, también ha optimizado procesos ya creados y tablas de base de datos, para mejorar rendimientos y tiempos de carga. Ha diseñado y creado visualizaciones, tanto los dashboards con todos sus gráficos y KPIs, además de diseñar y crear los modelos para las herramientas de visualización.
Arquitectura de capas
Durante su ponencia, David Ortega, expuso sobre la importancia de tener en cuenta ciertos aspectos, condiciones y prácticas en la arquitectura de capas de datos en proyectos de Business Intelligence. Remarcando en ciertos aspectos clave como no quedarse con el desarrollo y su puesta en funcionamiento sino añadir también un fácil mantenimiento que permita la realización de mejoras o la gestión de accesos a los datos. Haciendo hincapié en la profundización de los pasos, técnicas y procesos adecuados a llevar a cabo para conseguirlo.
Arquitectura y modelización de datos en Business Intelligence
A la hora de desarrollar e implementar un proyecto de Business Inteligencie, con todos sus procesos, bases de datos y visualizaciones, hay que tener en cuenta ciertos aspectos, condiciones y prácticas. No solo es desarrollarlo y ver que funciona, sino también que tenga un fácil mantenimiento, se pueden hacer mejoras o que personas del negocio acceden a los datos. Principalmente hay dos arquitecturas de 2 capas y de 3 capas, para el desarrollo del modelado de las tablas.
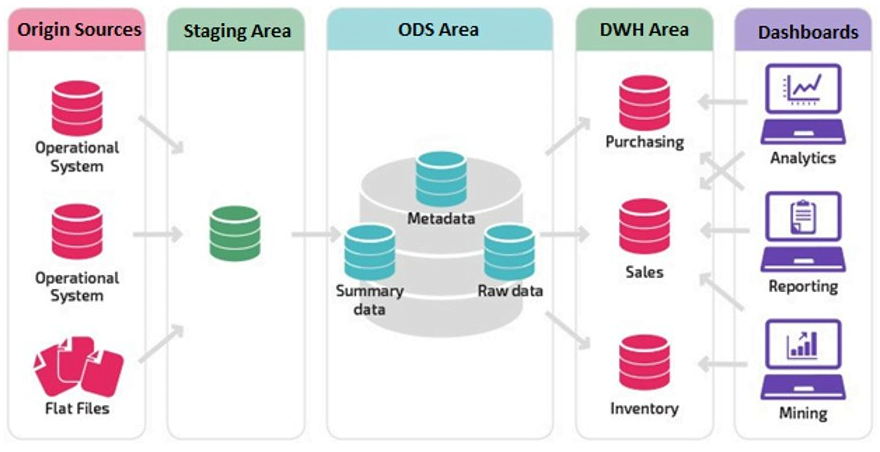
Lo primero es crear las capas de la arquitectura de datos y todo lo que conlleva. Por lo general se utilizan dos capas en la arquitectura. Una primera capa denominada ODS (Operational Data Store) y una segunda capa denominada DWH (Data Warehouse). La capa ODS integra datos de múltiples orígenes, donde se limpian datos, se realizan operaciones y se comprueba la integridad. Además de aplicar Data Quality y reglas de negocio. La capa de DWH es el almacén no volátil y variable en el tiempo, preparado para su explotación por las herramientas de visualización y los usuarios de negocio.

Entre las capas y los orígenes se suelen utilizar para el procesamiento de los datos, tablas temporales guardadas en memoria o tablas auxiliares guardada en la base de datos. Todo esto depende de varios factores como memoria disponible, complejidad de los cálculos, tiempo de procesamiento, etc.
En ocasiones se utiliza una arquitectura de tres capas, por delante de estas dos capas de datos, se suele crear una tercera capa de datos. Esta capa de datos se llama Staging y precede a la capa de ODS. En ella se guarda una copia exacta de los datos de origen, con el mismo esquema, tablas y nombres. El objetivo de esta capa es no interferir en la operativa diaria de las distintas aplicaciones y usuarios. Con ello se gana la ventaja de poder examina y realizar reprocesamientos sin interferir con las tablas de origen.